
目标检测与跟踪算法
目标检测
Object Detection in 20 Years: A Survey
论文详解
概述
核心问题
- 分类问题:即图片(或某个区域)中的图像属于哪个类别
- 定位问题:目标可能出现在图像的任何位置
- 大小问题:目标有各种不同的大小
- 形状问题:目标可能有各种不同的形状
算法分类
| Anchor Based模型 | Anchor Free模型 | |
|---|---|---|
| One-stage模型 | YoloV2-5系列、SSD、RetinaNet | YoloV1、FCOS、CornerNet |
| Two-stage模型 | Faster RCNN、Cascade RCNN、MaskRCNN |
- two stage:
- 先进行区域生成,该区域称为region proposal(RP,一个有可能包含物体的预选框);再通过卷积神经网络进行样本分类
- 任务流程:特征提取—生成RP—分类/定位回归
- 常见two stage:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN
- one stage:
- 不用RP,直接在网络中提取特征来预测物体的分类和位置
- 任务流程:特征提取—分类/定位回归
- 常见one stage:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD、RetinaNet
目标检测分为两大系列——RCNN系列和YOLO系列:
- RCNN系列是
基于区域检测的代表性算法 - YOLO是
基于区域提取的代表性算法 - 还有著名的SSD是基于前两个系列的改进
发展脉络
| 2014 | 2015 | 2016 | 2017 | 2018 |
|---|---|---|---|---|
| R-CNN | Fast R-CNN Faster R-CNN YOLO |
YOLO SSD |
YOLOv2 RetinaNet Mask R-CNN FPN |
YOLOv3 Cascade R-CNN |
| 2020 | 2022 | 2023 | |
|---|---|---|---|
| YOLOv4 YOLOv5 EfficientDet |
YOLOv6(美团) YOLOv7 |
YOLOv8 |
指标和数据
map指标
YOLO 模型的评估指标——IOU、Precision、Recall、F1-score、mAP
mAP@0.5
在YOLO模型中,你会见到mAP@0.5这样的表现形式,这种形式表示在IOU阈值为0.5的情况下,mAP的值为多少。当预测框与标注框的IOU大于0.5时,就认为这个对象预测正确,在这个前提下再去计算mAP。一般来说,mAP@0.5即为评价YOLO模型的指标之一
mAP@[0.5:0.95]
YOLO模型中还存在mAP@[0.5:0.95]这样一种表现形式,这形式是多个IOU阈值下的mAP,会在q区间[0.5,0.95]内,以0.05为步长,取10个IOU阈值,分别计算这10个IOU阈值下的mAP,再取平均值。mAP@[0.5:0.95]越大,表示预测框越精准,因为它去取到了更多IOU阈值大的情况
数据集准备
RCNN系列
候选区域的产生

很多目标检测技术都会涉及候选框(bounding boxes)的生成,物体候选框获取当前主要使用图像分割与区域生长技术。区域生长(合并)主要由于检测图像中存在的物体具有局部区域相似性(颜色、纹理等)
滑动窗口法- 滑动:首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动
- 检测:每次滑动时候对当前窗口执行分类器(分类器是事先训练好的)。如果当前窗口得到较高的分类概率,则认为检测到了物体
- 不同尺度:对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,
- NMS:采用非极大值抑制(Non-Maximum Suppression, NMS)的方法进行筛选,最终,经过NMS筛选后获得检测到的物体
选择性搜索:selective search(简称SS)方法是当下最为熟知的图像bounding boxes提取算法,由Koen E.A于2011年提出只对图像中最有可能包含物体的区域进行搜索以此来提高计算效率,图像中物体可能存在的区域应该是有某些相似性或者连续性区域的
- 分割:对输入图像进行分割算法产生许多小的子区域
- 合并:根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并
- 候选框:每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域外切矩形就是通常所说的候选框
滑窗法简单易于理解,但是不同窗口大小进行图像全局搜索导致效率低下,而且设计窗口大小时候还需要考虑物体的长宽比。所以,对于实时性要求较高的分类器,不推荐使用滑窗法
选择搜索计算效率优于滑窗法,由于采用子区域合并策略,所以可以包含各种大小的疑似物体框,合并区域相似的指标多样性,提高了检测物体的概率
数据表示
预测输出可以表示为:
其中, 为预测结果的置信概率, 为边框坐标, 为属于某个类别的概率,通过预测结果,实际结果,构建损失函数,损失函数包含了分类、回归两部分组成
效果评估
使用IoU(Intersection over Union,交并比)来判断模型的好坏。所谓交并比,是指预测边框、实际边框交集和并集的比率,一般约定0.5为一个可以接受的值
预测结果中,可能多个预测结果间存在重叠部分,需要保留交并比最大的、去掉非最大的预测结果,这就是非极大值抑制(Non-Maximum Suppression,简写作NMS),非极大值抑制的流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空
bbox回归训练:其实就是训练 矩阵向 矩阵靠齐的过程
【目标检测】基础知识:IoU、NMS、Bounding box regression
即: 给定 ,寻找一种映射,使得
主要操作就是平移+缩放
rcnn
RCNN
分为三个module:
独立类别的候选区域(category-independent region proposals),生成一组对检测器可用的检测坐标
- 常见的候选区生成的方法有很多(objectness、selective search、category-independent object proposals、constrained parametric min-cuts (CPMC) 、multi-scale combinatorial grouping),本文用的是选择搜索。产生了2000个候选区域(region proposal)
使用卷积神经网络从每个区域从提取固定的特征向量
本文每个区域提取到的固定长度的特征向量是4096,使用的网络是AlexNet
需要注意的是 Alextnet 的输入图像大小是,而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到的尺寸(就是只有候选框里保留,剩余部分填充其它像素,或者先在候选框周围加上16的padding,再进行各向异性缩放,这种形变使得mAp提高了3到5个百分点)。有一个细节,在对 Region 进行变换的时候,首先对这些区域进行膨胀处理,在其 box 周围附加了 p 个像素,也就是人为添加了边框,在这里 p=16
在 ImageNet 上先进行预训练,然后利用成熟的权重参数在 PASCAL VOC 数据集上进行 fine-tune,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。
训练过程:首先对 PASCAL VOC数据集 进行Selective Search,搜索到2000个Region Proposal对Pre-trained模型进行fine-tuning。将原来预训练模型最后的1000-way的全连接层(分类层)换成21-way的分类层(20类物体+背景),然后计算每个region proposal和ground truth 的IoU,对于IoU>0.5的region proposal被视为正样本,否则为负样本(即背景)。另外,由于对于一张图片的多有候选区域来说,负样本是远远大于正样本数,所以需要将正样本进行上采样来保证样本分布均衡。在每次迭代的过程中,选择层次采样,每个mini-batch中采样两张图像,从中随机选取32个正样本和96个负样本组成一个mini-batch(128,正负比:1:3)。我们使用0.001的学习率和SGD来进行训练,提取特征的CNN网络经过了预训练和微调后不再训练,就固定不变了,只单纯的作为一个提特征的工具了
SVM线性分类器,对特征进行分类:在训练CNN提取特征时,设置的IOU是0.5以上为正样本,小于0.5的是负样本。但在SVM分类中,只有bbox完全包围了物体(也可以理解为IOU>0.7时)才是正样本,IOU小于0.3的是负样本。前者是大样本训练,后者是小样本训练,svm适用于少样本训练,如果用CNN反而不合适
- 用SVM对每个特征向量进行评分,然后用非极大值抑制
简单说就是:
- 给定一张输入图片,从图片中提取 2000 个类别独立的候选区域
- 对于每个区域利用 CNN 抽取一个固定长度的特征向量
- 再对每个特征向量利用 SVM 进行目标分类
测试步骤:
Region proposal的确定:VOC测试图像输入后,利用SS搜索方法,根据相似度从大到小排序,筛选出2000个region proposals
RP的Features提取:将RP通过resize成,然后分别输入进CNN特征提取网络,得到了2000个4096维features
SVM分类:将
(2000,4096)维矩阵输入进SVM分类器中,最终得到(2000,21)矩阵。每一行的21个列值,分别代表了这个RP属于每一个类的可能性。通过提前设置好的background阈值和所属于类的阈值,筛选出满足条件的m个RP区域BoundingBox-Regression:将
(m,4096)维矩阵输入进(4096,4)的回归矩阵 d dd 中,最后输出(m,4)偏移矩阵。代表RP中心点的位置偏移 和 bbox的尺寸变换将SVM筛选出的m个RP区域对应的特征向量,组成
(m,4096)矩阵 代入(4096,4)的回归矩阵d中,最后输出(m,4)偏移矩阵Non-maximum suppression处理:只画出SVM筛选出的m个RP区域的修正后的检测框,进行非极大值抑制(NMS),得到最终检测结果
缺点:
- 重复计算,每个region proposal,都需要经过一个AlexNet特征提取,为所有的RoI(region of interest)提取特征大约花费47秒,占用空间
- selective search方法生成region proposal,对一帧图像,需要花费2秒
- 三个模块(提取、分类、回归)是分别训练的,并且在训练时候,对于存储空间消耗较大
spp-net
SPP-Net: 出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
所有的神经网络都是需要输入固定尺寸的图片,比如(ImageNet)、(LenNet)、等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度
为什么要固定输入图片的大小?:卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图,但是全连接层的参数就和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,所以需要规定输入的feature的大小,因此,固定长度的约束仅限于全连接层
SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出

金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量)
SPP-Net,整个过程是:
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别
难点
假设表示特征图上的坐标点,坐标点表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:
其中就是CNN中所有的strides的乘积,包含了池化、卷积的stride
fast-rcnn
Fast-Rcnn:提出了ROI pooling
R-CNN存在一些问题:
- 训练分多步:R-CNN的训练先要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归,另外region proposal也要单独用selective search的方式获得,步骤比较繁琐
- 时间和内存消耗大:在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间消耗还是比较大的
- 测试慢:每张图片的每个region proposal都要做卷积,重复操作太多
虽然在Fast RCNN之前有提出过SPPnet算法来解决RCNN中重复卷积的问题,但是SPPnet依然存在和RCNN一样的一些缺点比如:训练步骤过多,需要训练SVM分类器,需要额外的回归器,特征也是保存在磁盘上
因此Fast RCNN相当于全面改进了原有的这两个算法,不仅训练步骤减少了,也不需要额外将特征保存在磁盘上
基于VGG16的Fast RCNN算法的速度:
- 在训练速度上比RCNN快了将近9倍,比SPPnet快大概3倍
- 测试速度比RCNN快了213倍,比SPPnet快了10倍
在VOC2012上的mAP在66%左右
网络有两个输入:图像和对应的region proposal。其中region proposal由selective search方法得到,没有表示在流程图中
- 对每个类别都训练一个回归器,且只有非背景的region proposal才需要进行回归
- ROI pooling:ROI Pooling的作用是对不同大小的region proposal,从最后卷积层输出的feature map提取大小固定的feature map(ROI Pooling使用自适应(根据输入feature的大小自调整)池化区域,不再固定池化区域大小,而固定池化区域个数,这样就确保了输入什么大小的feature,输出的feature大小完全相等,等于池化区域个数)。
简单讲可以看做是SPPNet的简化版本,因为全连接层的输入需要尺寸大小一样,所以不能直接将不同大小的region proposal映射到feature map作为输出,需要做尺寸变换。在文章中,VGG16网络使用的参数,即将一个的region proposal分割成大小的网格,然后将这个region proposal映射到最后一个卷积层输出的feature map,最后计算每个网格里的最大值作为该网格的输出,所以不管ROI pooling之前的feature map大小是多少,ROI pooling后得到的feature map大小都是 - 简单说ROI pooling就是:
- 把图片上selective search选出的候选框映射到特征图上对应的位置,这个映射是根据输入图片缩小的尺寸来的;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同)
- 对每个sections进行max pooling操作; 这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps
- 两个loss:第一个优化目标是分类,使用softmax(就不用像前面的R-CNN和SPP再用SVM了),第二个优化目标是bbox regression,使用了一个平滑的L1-loss
ROI Pooling 与 SPP 的区别:
通过上面的介绍,可以看到两者起到的作用是相同的,把不同尺寸的特征输入转化为相同尺寸的特征输出。SPP针对同一个输入使用了多个不同尺寸的池化操作,把不同尺度的结果拼接作为输出;而ROI Pooling可看作单尺度的SPP,对于一个输入只进行一次池化操作
可以看出Fast RCNN主要有3个改进:
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算
- 用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入
- 将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器
- 在实际训练中,每个mini-batch包含2张图像和128个region proposal(或者叫ROI),也就是每张图像有64个ROI。然后从这些ROI中挑选约25%的ROI,这些ROI和ground truth的IOU值都大于0.5。另外只采用随机水平翻转的方式增加数据集
- 测试的时候则每张图像大约2000个ROI
总结:
Fast RCNN将RCNN众多步骤整合在一起,不仅大大提高了检测速度,也提高了检测准确率。其中,对整张图像卷积而不是对每个region proposal卷积,ROI Pooling,分类和回归都放在网络一起训练的multi-task loss是算法的三个核心。另外还有SVD分解等是加速的小贡献,数据集的增加时mAP提高的小贡献
当然Fast RCNN的主要缺点在于region proposal的提取使用selective search,目标检测时间大多消耗在这上面(提region proposal 2~3s,而提特征分类只需0.32s),这也是后续Faster RCNN的改进方向之一
缺点:
- 依旧采用selective search提取region proposal(耗时2~3秒,特征提取耗时0.32秒)
- 无法满足实时应用,没有真正实现端到端训练测试
- 利用了GPU,但是region proposal方法是在CPU上实现的
总结
RCNN:
- 给定一张输入图片,通过 Selective Search从图片中提取 2000 个类别独立的候选区域
- 对于每个区域利用 CNN 抽取一个固定长度的特征向量
- 对每个特征向量利用 SVM 进行目标分类
- 对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标
缺点:
- 重复计算,每个region proposal,都需要经过一个AlexNet特征提取
- selective search方法生成region proposal,对一帧图像,需要花费2秒
- 三个模块(提取、分类、回归)是分别训练的,并且在训练时候,对于存储空间消耗较大
- 训练分为多个阶段,步骤繁琐:微调网络+训练SVM+训练边框回归器
- SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新
SPPNet: 金字塔池化层
当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量)
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样
- 特征提取阶段,把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量,只需要一次对整张图片进行特征提取,速度会大大提升
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别
Fast-RCNN:
- 给定一张输入图片,通过 Selective Search从图片中提取 2000 个类别独立的候选区域
- 对每个类别都训练一个回归器,且只有非背景的region proposal才需要进行回归。
- ROI pooling:ROI Pooling的作用是对不同大小的region proposal,从最后卷积层输出的feature map提取大小固定的feature map。简单讲可以看做是SPPNet的简化版本(把图片上selective search选出的候选框映射到特征图上对应的位置,这个映射是根据输入图片缩小的尺寸来的),因为全连接层的输入需要尺寸大小一样,所以不能直接将不同大小的region proposal映射到feature map作为输出,需要做尺寸变换
- 两个loss:第一个优化目标是分类,使用softmax(就不用像前面的R-CNN和SPP再用SVM了),第二个优化目标是bbox regression,使用了一个平滑的L1-loss
优点
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算
- 用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样
- 将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器
三个核心:对整张图像卷积、ROI Pooling、分类和回归一起训练的multi-task loss
主要缺点在于region proposal的提取使用selective search,目标检测时间大多消耗在这上面
相比R-CNN,主要两处不同:
- 最后一层卷积层后加了一个ROI pooling layer;
- 损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练
faster-rcnn
推荐这篇文章-Object Detection and Classification using R-CNNs
Faster R-CNN:提出了RPN(region proposal network)
主要就是多了一个RPN(region proposal network),就是在卷积提取特征之后,多出一条路来进行候选框的提取
推荐有关RPN层的文章:RPN层解析
RPN只是将框内认为是目标,框外认为是背景,做了个二分类,至于框内目标具体是啥,最终是交给分类网络去做

Faster-RCNN: RPN(region proposal network),就是在卷积提取特征之后,多出一条路来进行候选框的提取
- 将整张图片输入CNN,进行特征提取
- 用RPN生成建议窗口(proposals),每张图片生成300个建议窗口
- 通过RoI pooling层使每个RoI生成固定尺寸的feature map
- 利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练
相比Fast R-CNN,主要两处不同: - 使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
- 产生建议窗口的CNN和目标检测的CNN共享
如何高效快速产生建议框?
Faster R-CNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高
Yolo系列

Yolov1
网络结构

输出层的含义
\begin{array}{l}
loss = \lambda{\text {coord }} \sum{i=0}^{S^{2}} \sum{j=0}^{B} \mathbb{1}{i j}^{\mathrm{obj}}\left(x{i}-\hat{x}{i}\right)^{2}+\left(y{i}-\hat{y}{i}\right)^{2} \
\qquad + \lambda{\text {coord }} \sum{i=0}^{S^{2}} \sum{j=0}^{B} \mathbb{1}{i j}^{\mathrm{obj}}\left(\sqrt{w{i}}-\sqrt{\hat{w}{i}}\right)^{2}+\left(\sqrt{h{i}}-\sqrt{\hat{h}{i}}\right)^{2} \
\qquad +\sum{i=0}^{S^{2}} \sum{j=0}^{B} \mathbb{1}{i j}^{\mathrm{obj}}\left(C{i}-\hat{C}_{i}\right)^{2} \
\qquad + \lambda{\text {noobj }} \sum{i=0}^{S^{2}} \sum{j=0}^{B} \mathbb{1}{i j}^{\mathrm{noobj}}\left(C{i}-\hat{C}{i}\right)^{2} \
\qquad +\sum{i=0}^{S^{2}} \mathbb{1}{i}^{\mathrm{obj}} \sum{c \in \text { classes }} \left(p{i}(c)-\hat{p}_{i}(c)\right)^{2}
\end{array}
Score{i j} = P ( C{i} | Object ) * Confidence _{j}
3表示三个候选框,4表示的是xywh的位置信息,1表示是否为背景,20为物体的类别数(这里用的是voc数据集)
因为有三个输出,因此该网络有个预测框
对于这些预测框,如果其与任何真实框的IoU大于一定的阈值(如0.5),则将其分配给对应的输出层作为正样本。否则,将其视为负样本
YOLOv3 使用的损失函数是组合了多个部分的综合损失函数,其中包括定位损失(Localization Loss)、分类损失(Classification Loss)和置信度损失(Confidence Loss)
只有正样本才有这三类损失,而负样本只有置信度损失
以下是 YOLOv3 的损失函数的伪代码实现,包含详细注释:
1 | def yolo_loss(pred_boxes, pred_cls, target_boxes, target_cls): |
正负样本数
在 YOLOv3 中,通常会为每个目标选择一个正样本,即与真实目标框具有最高 IoU 的预测框。这确保了每个目标都有至少一个正样本来参与损失函数的计算和网络的训练。
至于负样本的选择,一般会设置一个阈值来确定预测框与真实框之间的 IoU 阈值。如果预测框的 IoU 低于该阈值,则被视为负样本。对于每个负样本,可以选择保留一定数量的负样本,以确保正负样本的平衡性。
具体来说,关于正负样本的选择数量并没有一个固定的标准,它可以根据具体的数据集和应用场景来确定。在实践中,可以根据数据集的统计信息和训练效果进行调整,以找到一个适合的正负样本比例,从而平衡目标检测的准确性和效率。
yolov5

Yolov8
目标检测
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
tensorRt加速
可以用tensorRt加速,环境教程可以参考这个文档
进行tensort加速,cmake编译失败,缺少zlibwapi.dll文件,解决办法,去cudnn官网下载zlib123dllx64
lib文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib
dll文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\bin
YoloV8提供了导出工具,详见文档,python代码导出可以这样子写
1 | def run(): |
或者直接命令行执行
1 | yolo mode=export model=yolov8s.pt format=engine device=0 workspace=8 batch=4 dynamic=True |
关键参数如下:
- device: 其中device必须是GPU,可以是多张显卡
- workspace: TensorRT: workspace size (GB)
- batch: 最大批次大小,当设置参数时必须有
dynamic=True,可以运行最大不超过batch的数量 - dynamic: 动态参数,ONNX/TF/TensorRT: dynamic axes
- imgsz: image size as scalar or (h, w) list, i.e. (640, 480)
注意事项:
TensorRT发布的模型(engine)不能跨平台使用
例如linux发布的模型不能在windows下用
TensorRT发布的模型需要在相同GPU算力(compute capability)的情况下使用
否则会导致compute capability不匹配问题,例如算力6.1发布的模型不能在7.5上用
动态batch和动态宽高的处理方式
动态batch:源自tensorRT编译时对batch的处理,若静态batch则意味着无论你多少图,都按照固定大小batch推理,耗时是固定的
- 导出模型时,注意view操作不能固定batch维度数值,通常写-1
- 导出模型时,通常可以指定dynamic_axes,实际上不指定也没关系
动态宽高:源自onnx导出时指定的宽高是固定的,trt编译时也得到固定大小引擎,此时若你想得到一个不同大小的trt引擎时,就需要动态宽高的存在。而使用trt的动态宽高会带来太多不必要的复杂度,这里使用中间方案,编译时修改onnx输入实现相对动态,避免重回pytorch再做导出
不建议使用dynamic_axes指定0以外的维度为动态,复杂度太高,并且存在有的layer不支持,这种需求也不常用,性能也很差
真正需要的,是onnx文件已经导出,但是输入shape固定了,此时希望修改这个onnx的输入shape
步骤一: 使用TRT::compile函数的inputsDimsSetup参数重定义输入的shape
步骤二: 使用TRT:set_layer_hook_reshape钩子动态修改reshape的参数实现适配
其他检测系列
SSD
FPN
Feature Pyramid Networks for Object Detection
概述
FPN(feature pyramid networks) 是何凯明等作者提出的适用于多尺度目标检测算法
原来多数的object detection算法(比如 faster rcnn)都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略
另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的,这里主要借鉴了
- ResNet的残差: 结合了浅层特征和深层特征
- SSD的检测策略: 在不同分辨率的特征图上分别做预测
特征金字塔图示,越粗表示特征语义更强

图中将特征金字塔和其他的金字塔做了比较
- (a)是传统中的图片金字塔,图片缩放到不同的大小,分别预测,每个特征提取/预测都是独立进行的,同一张图片的不同分辨率,也很难共享它们中间提取的特征,让模型预测的过程费时费力
- (b)是原生的CNN提取的特征,由于后续存在池化和降采样,浅层网络的特征图可以保留更多的分辨率,但是特征语义较为低级
- (c)是SSD中的特征,把不同分辨率特征,在不同分辨率的特征上直接预测,那么大物体小物体都能预测到,但仍存在底层特征语义不够和最高分辨率不高的问题
- (d)是FPN中用的特征金字塔,结合深浅特征,兼顾分辨率与特征语义
RetinaNet
RetinaNet是使用FPN和Focal Loss(详情看本站深度学习核心之损失函数部分)的目标检测模型,能够有效解决类别不平衡问题
它通过特征金字塔网络生成多尺度的特征图,并使用Focal Loss重点关注难以分类的样本,从而提高了检测性能

DETR
继Transformer应用于图像分类后,Transformer应用于图像目标检测的开山之作–DEtection TRansformer,其大大简化了目标检测的框架,更直观
DETR是Facebook团队于2020年提出的基于Transformer的端到端目标检测,没有非极大值抑制NMS后处理步骤、没有anchor等先验知识和约束,整个由网络实现端到端的目标检测实现,大大简化了目标检测的pipeline。结果在COCO数据集上效果与Faster RCNN相当,在大目标上效果比Faster RCNN好,且可以很容易地将DETR迁移到其他任务例如全景分割

目标跟踪
万字长文 | 多目标跟踪最新综述(基于Transformer/图模型/检测和关联/孪生网络)
目标跟踪 = 目标检测+目标跟踪算法
目标追踪算法分为单目标追踪SOT(Single-Object Track)和多目标追踪MOT(Multi-Object Track)[1][2]
- 在单目标跟踪中,使用给定的初始目标位置,在后续视频帧中对给定的物体进行位置预测
- 多目标跟踪算法,大部分都是不考虑初始目标位置的,目标可自行消失与产生
目标跟踪分类
目标跟踪通常可分为单目标跟踪和多目标跟踪两类
单目标跟踪
多目标跟踪
SDE(separate detecting and embeding)
每部分独立优化能够取得比较高的精度,缺点就是计算量会增加
JDE(joint detecting and embeding)
JDE将目标检测与REID特征提取放在一个网络,这样能有效减少计算量,但是多任务学习的精度会低些
解决的任务和视频目标检测相同的点在于都需要对每帧图像中的目标精准定位,不同点在于目标跟踪不考虑目标的识别问题
SDE将REID特征提取和目标检测分为两个独立网络来实现,这样做的优点是每部分独立优化能够取得比较高的精度,缺点就是计算量会增加;JDE将目标检测与REID特征提取放在一个网络,这样能有效减少计算量,但是多任务学习的精度目前来说还没有SDE高。在工程应用上我更偏向于JDE,毕竟跟踪要保证实时性,在能够提取一个不太差的REID特征基础上,加强检测器性能和优化数据关联部分也能一定程度上弥补REID特征不够好带来的性能损失
Sort
DeepSort

StrongSort
StrongSort相比于DeepSort的区别:
使用BoT替代CNN做外表特征的提取
使用EMA(exponential moving average:指数移动平均)策略更新新帧中的目标外观特征
EMA更新策略不仅提高了匹配质量,而且减少了时间消耗
在做Kalman filter之前,使用ECC(enhanced correlation coefficient:增强相关系数)进行相机运动补偿;并使用NSA Kalman代替Kalman进行运动特征获取
将运动信息和外观信息结合来进行匹配
使用Vanilla全局线性赋值代替了匹配级联
BotSort
ByteTrack
ByteTrack: Multi-Object Tracking by Associating Every Detection Box

依赖的算法
卡尔曼滤波
卡尔曼滤波被广泛应用于无人机、自动驾驶、卫星导航等领域
简单来说,其作用就是基于传感器的测量值来更新预测值,以达到更精确的估计
假设我们要跟踪小车的位置变化,如下图所示,蓝色的分布是卡尔曼滤波预测值,棕色的分布是传感器的测量值,灰色的分布就是预测值基于测量值更新后的最优估计
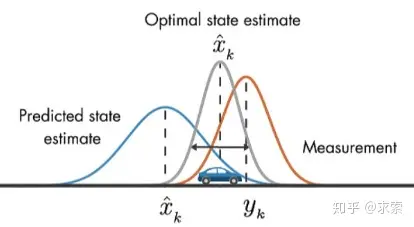
在目标跟踪中,需要估计track的以下两个状态:
均值(Mean):表示目标的位置信息,由bbox的中心坐标 (cx, cy),宽高比r,高h,以及各自的速度变化值组成
由8维向量表示为 x = [cx, cy, r, h, vx, vy, vr, vh],各个速度值初始化为0
协方差(Covariance ):表示目标位置信息的不确定性,由8x8的对角矩阵表示,矩阵中数字越大则表明不确定性越大,可以以任意值初始化
卡尔曼滤波分为两个阶段:(1) 预测track在下一时刻的位置,(2) 基于detection来更新预测的位置。
匈牙利匹配算法
先介绍一下什么是分配问题(Assignment Problem):假设有N个人和N个任务,每个任务可以任意分配给不同的人,已知每个人完成每个任务要花费的代价不尽相同,那么如何分配可以使得总的代价最小
举个例子,假设现在有3个任务,要分别分配给3个人,每个人完成各个任务所需代价矩阵(cost matrix)如下所示(这个代价可以是金钱、时间等等):
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | 15 | 40 | 45 |
| Person_2 | 20 | 60 | 35 |
| Person_3 | 20 | 40 | 25 |
怎样才能找到一个最优分配,使得完成所有任务花费的代价最小呢?
匈牙利算法(又叫KM算法)就是用来解决分配问题的一种方法,它基于定理:
如果代价矩阵的
某一行或某一列同时加上或减去某个数,则这个新的代价矩阵的最优分配仍然是原代价矩阵的最优分配
算法步骤(假设矩阵为N阶方阵):
- 对于矩阵的每一行,减去其中最小的元素
- 对于矩阵的每一列,减去其中最小的元素
- 用最少的水平线或垂直线覆盖矩阵中所有的0
- 如果线的数量等于N,则找到了最优分配,算法结束,否则进入步骤5
- 找到没有被任何线覆盖的最小元素,每个没被线覆盖的行减去这个元素,每个被线覆盖的列加上这个元素,返回步骤3
继续拿上面的例子做演示:
step1 每一行最小的元素分别为15、20、20,减去得到:
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | 0 | 25 | 30 |
| Person_2 | 0 | 40 | 15 |
| Person_3 | 0 | 20 | 5 |
step2 每一列最小的元素分别为0、20、5,减去得到:
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | 0 | 5 | 25 |
| Person_2 | 0 | 20 | 10 |
| Person_3 | 0 | 0 | 0 |
step3 用最少的水平线或垂直线覆盖所有的0,得到:
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | 5 | 25 | |
| Person_2 | 20 | 10 | |
| Person_3 |
step4 线的数量为2,小于3,进入下一步;
step5 现在没被覆盖的最小元素是5,没被覆盖的行(第一和第二行)减去5,得到:
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | -5 | 0 | 20 |
| Person_2 | -5 | 15 | 5 |
| Person_3 | 0 | 0 | 0 |
被覆盖的列(第一列)加上5,得到:
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | 0 | 0 | 20 |
| Person_2 | 0 | 15 | 5 |
| Person_3 | 5 | 0 | 0 |
跳转到step3,用最少的水平线或垂直线覆盖所有的0,得到:
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | |||
| Person_2 | |||
| Person_3 |
step4:线的数量为3,满足条件,算法结束
显然,将任务2分配给第1个人、任务1分配给第2个人、任务3分配给第3个人时,总的代价最小(0+0+0=0):
所以原矩阵的最小总代价为40+20+25=85
| Task_1 | Task_2 | Task_3 | |
|---|---|---|---|
| Person_1 | 15 | 40 | 45 |
| Person_2 | 20 | 60 | 35 |
| Person_3 | 20 | 40 | 25 |
sklearn里的linear_assignment()函数以及scipy里的linear_sum_assignment()函数都实现了匈牙利算法
1 | import numpy as np |
追踪指标
MOTA(Multiple Object Tracking Accuracy): 指标体现多目标跟踪的准确度
MOTA指标是衡量多目标跟踪算法精确性方面最重要的指标,以1为最佳情况,
数值越高代表跟踪精确度越好IDF1: 指标代表被检测和跟踪的目标中获取正确的ID的检测目标的比例,综合考虑ID准确率和ID召回率,代表两者的调和均值
其中,IDP代表ID跟踪的准确率,IDR代表ID跟踪的召回率,IDF1指标更聚焦于跟踪算法跟踪某个目标的时间长短,考察跟踪的连续性和重识别的准确性,IDF1以1为最佳情况,
数值越高代表跟踪特定目标的精度越好HOTA
道路监控管理
- Roboflow数据集标注
- 目标检测算法_模型训练
- 目标跟踪算法_ByteTrack(实时性)
- 物体检测分类
- 主动学习和强化学习
主动学习:是一种通过主动选择最有价值的样本进行标注的机器学习或人工智能方法。其目的是使用尽可能少的、高质量的样本标注使模型达到尽可能好的性能。也就是说,主动学习方法能够提高样本及标注的增益,在有限标注预算的前提下,最大化模型的性能,是一种从样本的角度,提高数据效率的方案,因而被应用在标注成本高、标注难度大等任务中,例如医疗图像、无人驾驶、异常检测、基于互联网大数据的相关问题
强化学习:强化学习是一个非常吸引人的人工智能领域,2016年 Alpha Go在围棋领域挑战李世石,以几乎碾压的结果夺冠,引起了人们对于人工智能的广泛讨论。2019年Alpha Star横空出世,在复杂的星际争霸2游戏中达到能和人类顶级玩家PK的水平,登上Nature。这两次与人类顶级玩家的抗衡之战,背后的技术都是强化学习。强化学习是机器学习领域的一个分支,强调基于环境而行动,以取得最大化的长期利益。与监督学习、非监督学习不同,监督学习解决如分类、回归等感知和认知类的任务,而强化学习处理决策问题,着重于环境的交互、序列决策、和长期收益。强化学习与环境的交互模式可以抽象为:智能体Agent在环境Environment中学习,根绝环境的状态State,执行动作Action,并根据环境反馈的奖励Reward来指导输出更好的动作