
deepseek专题
deepseek资讯
Deepseek开源了从1.5B-671B的一系列模型。包括在Deepseek-v3基础上训练的Deepseek-R1,和只依赖RL训练的中间模型R1-zero。以及一系列基于Qwen和Llama模型,从Deepseek-R1蒸馏得到的小模型。这些模型在输出格式和输出质量上相比之前的开源模型(如Qwen团队的QwQ-32B)有显著改进。
蒸馏模型包括基于Qwen2.5-math的1.5B和7B模型,基于Qwen2.5的14B和32B模型,基于Llama3系列的8B和70B模型。基本包括了目前稠密模型除3B级别外的所有主流尺寸。
Deepseek-R1基本达到了OpenAI o1的水平,并且在部分领域领先。API成本低,并且模型权重开源。
模型Benchmark对比
以下Benchmark来自Deepseek-R1的官方技术报告,总的来说:
- DeepSeek-R1-Distill-Qwen-1.5B:基于
Qwen2.5-math-1.5B训练,与更大型的模型相比仍有较大差距。可以在手机等移动设备使用 - DeepSeek-R1-Distill-Qwen-7B:基于
Qwen2.5-math-7B训练,性能接近于先前开源SOTA模型(QwQ-32B-preview),但在某些指标上仍与闭源模型o1-mini存在差距 - DeepSeek-R1-Distill-Qwen-14B:基于
Qwen2.5-14B训练,进一步提升了模型性能,在性能上超越了先前开源SOTA模型(QwQ-32B-preview),并且缩小了与顶级闭源模型的差距 - DeepSeek-R1-Distill-Qwen-32B:基于
Qwen2.5-32B训练,是该系列中的高性能模型,在多个指标上超过了o1-mini等闭源模型 - DeepSeek-R1-Distill-Llama-8B:基于
Llama3.1-8B训练,展示了在不同架构下的适应性和性能,总体略逊于基于Qwen系列训练的模型,但在英文背景下可能更好 - DeepSeek-R1-Distill-Llama-70B:基于
Llama3.3-70B-Instruct训练,是该系列中参数量最大的模型,质量比Qwen-32B的蒸馏版本略好
对于8GB显存及以下的GPU,建议DeepSeek-R1-Distill-Qwen-7B
不同的版本
DeepSeek 模型家族功能与特点整理
DeepSeek-Coder(代码专家)
- 发布时间:2023 年 10 月
- 功能特点:专治「写代码手残党」,程序员的好基友。
- 帮助补全代码、找 Bug,甚至从零生成小程序。
- 训练数据中约 87% 都是代码,擅长应对各类编程问题。
- 适用场景:编程开发、代码调试、自动化生成小型程序。
DeepSeek-Math(数学学霸)
- 发布时间:2024 年 2 月
- 功能特点:数学竞赛级选手,数学爱好者的理想伴侣。
- 能解决高难度数学问题,提供清晰详细的解题步骤。
- 水平接近 GPT-4 和谷歌 Gemini,无需查资料即可完成复杂运算。
- 适用场景:数学学习、竞赛备考、高阶数学应用。
DeepSeek-V3(全能战士)
- 发布时间:2024 年 12 月
- 功能特点:六边形战士,综合能力最强。
- 支持推理、文案撰写、数据分析,功能全面。
- 性能与 GPT-4、Claude 3.5 相近,是企业和高端用户的首选。
- 训练成本极高:耗资 500 多万美元,使用 2000 多块顶级显卡。
- 适用场景:商业决策、高端研究、复杂任务处理。
DeepSeek-R1(经济适用型)
- 发布时间:2025 年 1 月
- 功能特点:主打高性价比,开源免费。
- 性能媲美 OpenAI 商用模型,适配多种设备和场景。
- 提供多种体型选择,从轻量级(可在手机上运行)到大型服务器专用版本,可根据需求自由选择。
- 适用场景:日常使用、企业服务、开发与实验。
DeepSeek-R1 系列提供多种参数规模(B = 10 亿参数),用户可以根据需求选择合适的体型:
1.5B-14B(迷你版)
- 特点:轻量级,加载快、省电。
- 能力:快速响应,适合简单任务。
- 适用场景:查天气、轻量聊天、短文案撰写。
- 运行环境:可在手机和低配置设备上使用。
32B-70B(中杯版)
- 特点:中等规模,提供专业级支持。
- 能力:适合更复杂任务,如法律文件分析、行业报告生成。
- 适用场景:企业客服、专业写作。
- 运行环境:需中等配置的电脑或服务器。
671B(巨无霸版)
- 特点:顶级规模,学霸级表现。
- 能力:解决竞赛题、写长篇小说、进行商业决策分析。
- 适用场景:科研机构、商业巨头、前沿研究。
- 运行环境:需顶级显卡服务器支持,普通设备无法运行。
| 模型名称 | 模型大小 | 运行命令 | 硬件配置 |
|---|---|---|---|
| DeepSeek-R1 | 671B | ollama run deepseek-r1:671b | 需要极高的硬件配置,显存需求超过 336GB A100 80G*6 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ollama run deepseek-r1:1.5b | 最低配置:8GB RAM,无显卡加速;适合老旧设备 |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ollama run deepseek-r1:7b | 最低配置:16GB RAM,8GB 显存(GPU 加速) |
| DeepSeek-R1-Distill-Llama-8B | 8B | ollama run deepseek-r1:8b | 最低配置:16GB RAM,8GB 显存(GPU 加速) |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ollama run deepseek-r1:14b | 最低配置:32GB RAM,26GB 显存(GPU 加速) |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ollama run deepseek-r1:32b | 最低配置:64GB RAM,64GB 显存(GPU 加速) |
| DeepSeek-R1-Distill-Llama-70B | 70B | ollama run deepseek-r1:70b | 最低配置:128GB RAM,140GB 显存(GPU 加速) |
选择合适的模型
如果追求速度
- 选择小模型(1.5B/7B/14B):加载快、响应迅速,适合用于手机 APP、网页插件等轻量应用场景。
如果注重精准性
- 选择中大模型(32B/70B):回答准确度更高,适合企业客服、专业写作等任务。
如果预算充足
- 选择巨无霸版(671B):综合能力最强,适合科研机构、大型企业,效果堪比专业博士团队。
总结:DeepSeek 系列提供了一系列功能强大的 AI 模型,从专注代码的 DeepSeek-Coder,到数学学霸 DeepSeek-Math,再到全能选手 DeepSeek-V3 和经济适用型 DeepSeek-R1,每款模型都能在各自的领域内提供卓越表现。无论是个人用户还是企业客户,都能找到最适合自己的选择!
部署
部署资源
部署资源,以下是未量化的(bf16的)
以下是华为官方给出的其他版本模型的部署资源最低要求及推理性能,供参考
昇腾一体机推荐配置:DeepSeek V3/R1及蒸馏模型推理服务部署推荐配置
| 模型名称 | 参数 | 产品 | 配置 | 系统吞吐 (Token/s) | 多用户并发数 (路) |
|---|---|---|---|---|---|
| DeepSeek V3 | 671B | Atlas 800I A2 | 1024GB | 1911 | 192 |
| DeepSeek R1 | 671B | Atlas 800I A2 | 1024GB | 1911 | 192 |
| DeepSeek-R1 Distill-Llama-70B | 70B | Atlas 800I A2 | 512GB | 3300 | 165 |
| DeepSeek-R1 Distill-Qwen-32B | 32B | Atlas 800I A2 | 256GB | 4940 | 247 |
| DeepSeek-R1 Distill-Qwen-14B | 14B | Atlas 800I A2 | 256GB | 7500 | 300 |
| DeepSeek-R1 Distill-Qwen-14B | 14B | Atlas 300I Duo | 1*Duo 96GB PCIE | 730 | 80 |
| DeepSeek-R1 Distill-Llama-8B | 8B | Atlas 300I Duo | 1*Duo 96GB PCIE | 956 | 115 |
| DeepSeek-R1 Distill-Qwen-7B | 7B | Atlas 300I Duo | 1*Duo 96GB PCIE | 956 | 115 |
| DeepSeek-R1 Distill-Qwen-1.5B | 1.5B | Atlas 300V | 1*300V 24GB PCIE | 432 | 16 |
- 数据截止至 2025.02.13
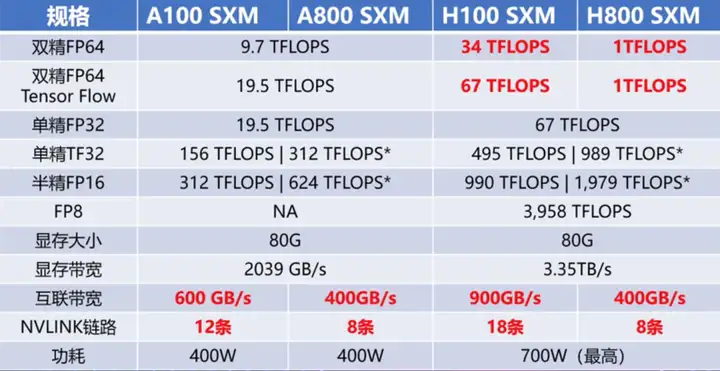
你如果是在a系列的卡上 a系列的卡就是不支持fp8 的 建议将fp8转为fp16
A100不支持FP8,一张A100显卡市价约10万
根据GPU型号,搭建算力中心的成本会有所不同:
- 一张A100显卡市价约10万
- 一张H100显卡市价约30万,A800/H800:价格略低于A100/H100
- 8卡昇腾910B-64G (1卡 2w左右,1台 16-18w)
| 模型 | 参数 | 体积(GB) | 精度 | 显存(GB) | 硬盘GB | 内存GB | 最低显卡配置(参考) |
|---|---|---|---|---|---|---|---|
| deepseek-r1 | 671B | 1400 | bf16 | 2048 | 2048 | 1024 | 8*昇腾910B-64G *4台 或8*昇腾910B-32G *8台 或A100-80G *24卡 |
| deepseek-r1 | 671B | 700 | fp8 | 1342 | 2048 | 512 | (910B不支持fp8)8*昇腾910B-64G *2.5台 8*昇腾910B-32G *5台 A100-80G *16卡(主要a系列跑不了fp8,这里只是供参考显存) |
| deepseek-r1 | 671B | 404 | gguf-Q4_K_M | 1024 | 512 | A100-80G *8卡 | |
| deepseek-r1 | 70B | 142 | bf16 | 512 | 256 | A100-80G *4卡 8*昇腾910B 32B满血4卡 70B满血8卡 |
量化模型部署
下载指定的文件夹
1
huggingface-cli download --resume-download unsloth/DeepSeek-R1-GGUF --local-dir DeepSeek-R1-Q4_K_M --include "DeepSeek-R1-Q4_K_M*" --cache /root/autodl-tmp/pretrained_model/cache
下载llama.cpp,并合并模型
1
2
3
4
5
6
7
8
9
10/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 中间好像要执行一些步骤
==> Next steps:
- Run these commands in your terminal to add Homebrew to your PATH:
echo >> /root/.bashrc
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /root/.bashrc
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
brew install llama.cpp1
llama-gguf-split --merge /root/autodl-tmp/pretrained_model/tokenizer/DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf /root/autodl-tmp/pretrained_model/tokenizer/DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M.gguf
安装ollama
1
2
3
4
5
6
7
8
9curl -fsSL https://ollama.com/install.sh | sh
4. 配置ollama,编辑`/etc/profile`,修改端口和模型存放位置
```cmd
export OLLAMA_MODELS=/root/autodl-tmp/pretrained_model/ollama_models
export OLLAMA_HOST=0.0.0.0:6006
export OLLAMA_FLASH_ATTENTION=1 # use flash attention
export OLLAMA_KEEP_ALIVE=-1 # keep the model loaded in memory启动ollama服务
1
2
3
4
5
6# 防止只用到单卡
export OLLAMA_SCHED_SPREAD=1
export CUDA_VISIBLE_DEVICES=0,1
# 可以考虑放后台
ollama start安装部署open_webui,
OLLAMA_BASE_URL填的是ollama的地址,如果是本地的就不需要填1
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
创建文件
DeepSeekQ1_Modelfile,用于创建ollama模型,你需要将第一行“FROM”后面的文件路径,改为下载并合并的.gguf文件的实际路径以下配置,在两张A800*80G上可运行,显存大约各自占用50G
1
2
3
4
5FROM /home/snowkylin/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 28
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"如果改为以下配置,在两张A800*80G上可运行,显存大约各自占用70G
1
2
3
4
5FROM /root/autodl-tmp/pretrained_model/tokenizer/DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 32
PARAMETER num_ctx 16384
PARAMETER temperature 0.6
TEMPLATE "<|User|>{{ .System }} {{ .Prompt }}<|Assistant|>"You may change the parameter values for
num_gpuandnum_ctxdepending on your machine specification参数说明:num_gpu指定加载进gpu的模型层数
创建 ollama 模型,第一个是模型的名字,第二个是配置文件
1
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile
启动模型
1
ollama run DeepSeek-R1-UD-IQ1_M --verbose
ollama其他命令
1️⃣ollama list:这个命令可以帮你查看当前部署的所有模型。
2️⃣ollama rm:这个命令就是用来删除模型的。
华为卡部署
【全网最全】昇腾 910B 部署满血版 DeepSeek-R1实用教程+踩坑记录
魔塔 deepseek-r1 bf16、hg deepseek-r1 bf16、hg unsloth deepseek-r1 bf16
前往昇腾社区/开发资源下载适配
DeepSeek-R1的镜像包:mindie_2.0.T3-800I-A2-py311-openeuler24.03-lts-aarch64.tar.gz
镜像加载后的名称:mindie:2.0.T3-800I-A2-py311-openeuler24.03-lts-aarch64
注意:量化需要使用mindie:2.0.T3版本
使用前提
宿主机上已经安装好固件与驱动,具体可参考安装驱动和固件
宿主机上已经安装好Docker
用户可使用如下命令查询当前环境是否安装驱动,若返回驱动相关信息说明已安装
1
npu-smi info
完成之后,请使用
docker images命令确认查找具体镜像名称与标签。1
docker load -i mindie:2.0.T3-800I-A2-py311-openeuler24.03-lts-aarch64(下载的镜像名称与标签)
各组件版本配套如下:
| 组件 | 版本 |
| ————— | ————————————————————————- |
| MindIE | 2.0.T3 |
| CANN | 8.0.T63 |
| PTA | 6.0.T700 |
| MindStudio | Msit: br_noncom_MindStudio_8.0.0_POC_20251231分支 |
| HDK | 24.1.0 |硬件要求
部署DeepSeek-R1模型用BF16权重进行推理至少需要4台Atlas 800I A2(8*64G)服务器()
用W8A8量化权重进行推理则至少需要2台Atlas 800I A2 (8*64G)()